Building your customized, on-premise AI servers tailored to your needs—maximizing performance while keeping your data private and secure.
Why Local AI Servers

Privacy & Security
Sensitive data stays within your infrastructure.
Full Control
No reliance on 3rd-party clouds.
Cost-Efficient
No recurring cloud fees, predictable costs.
High Performance
Optimized hardware with GPUs, high memory, and scalable storage.





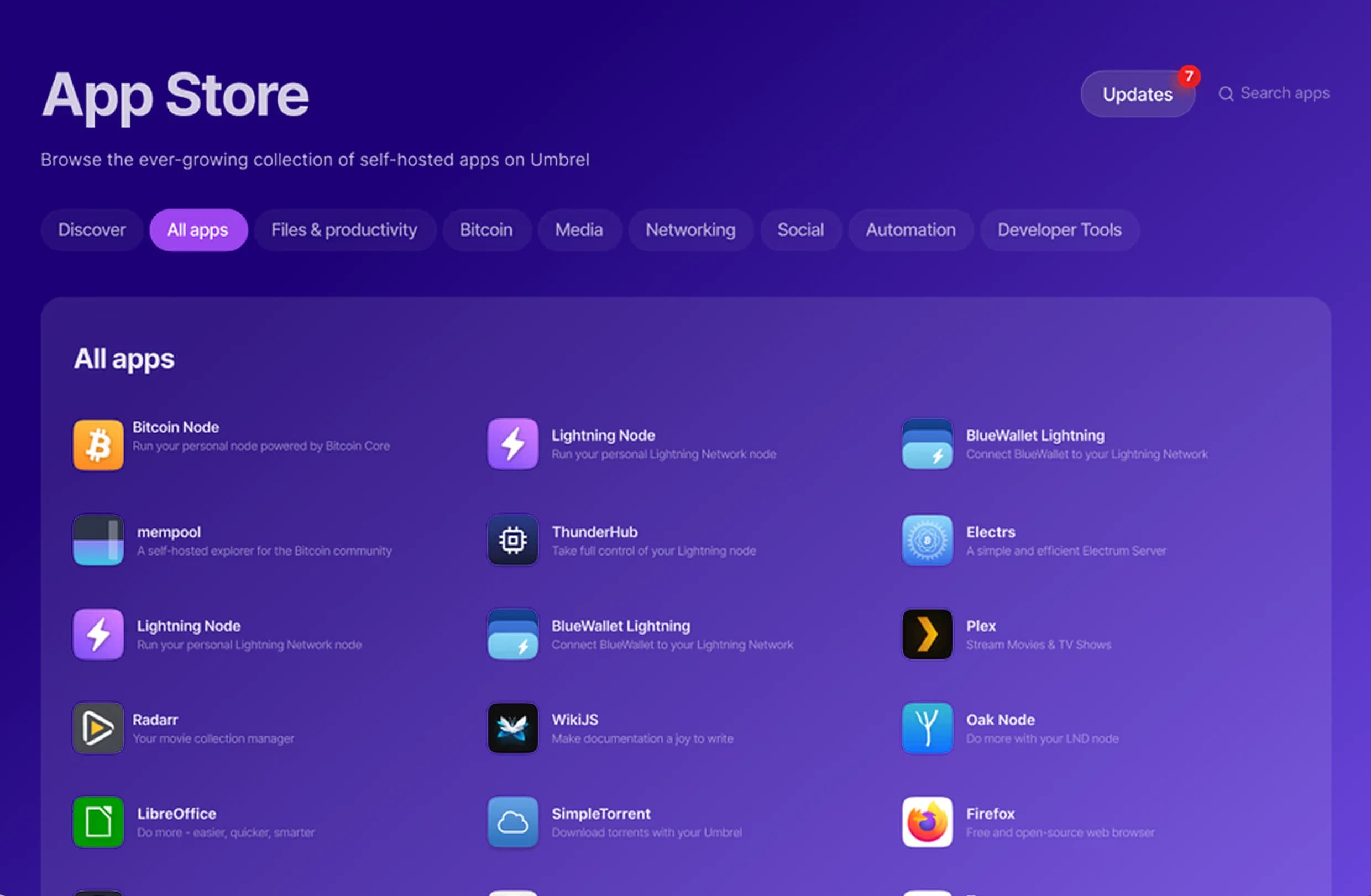
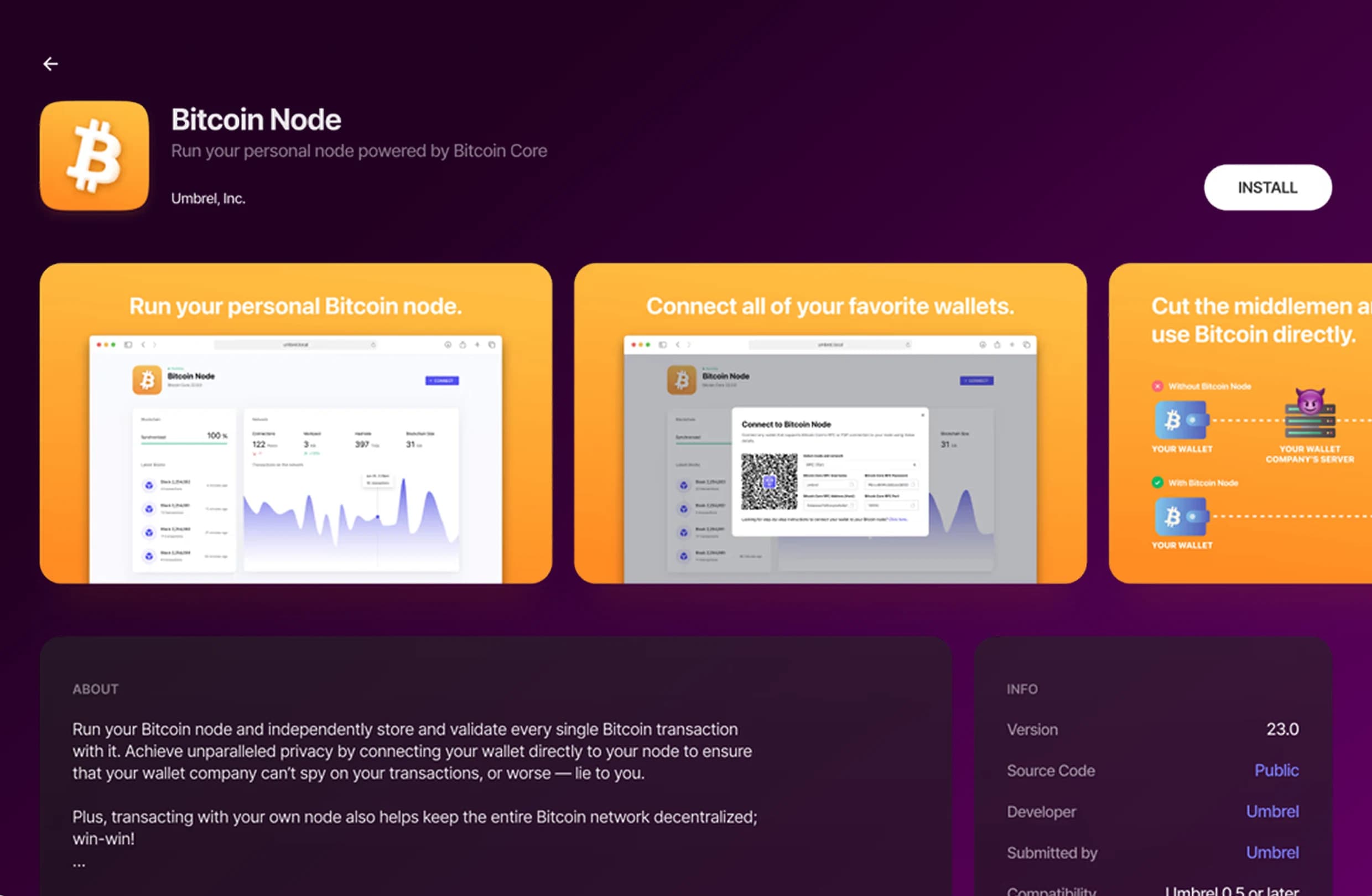
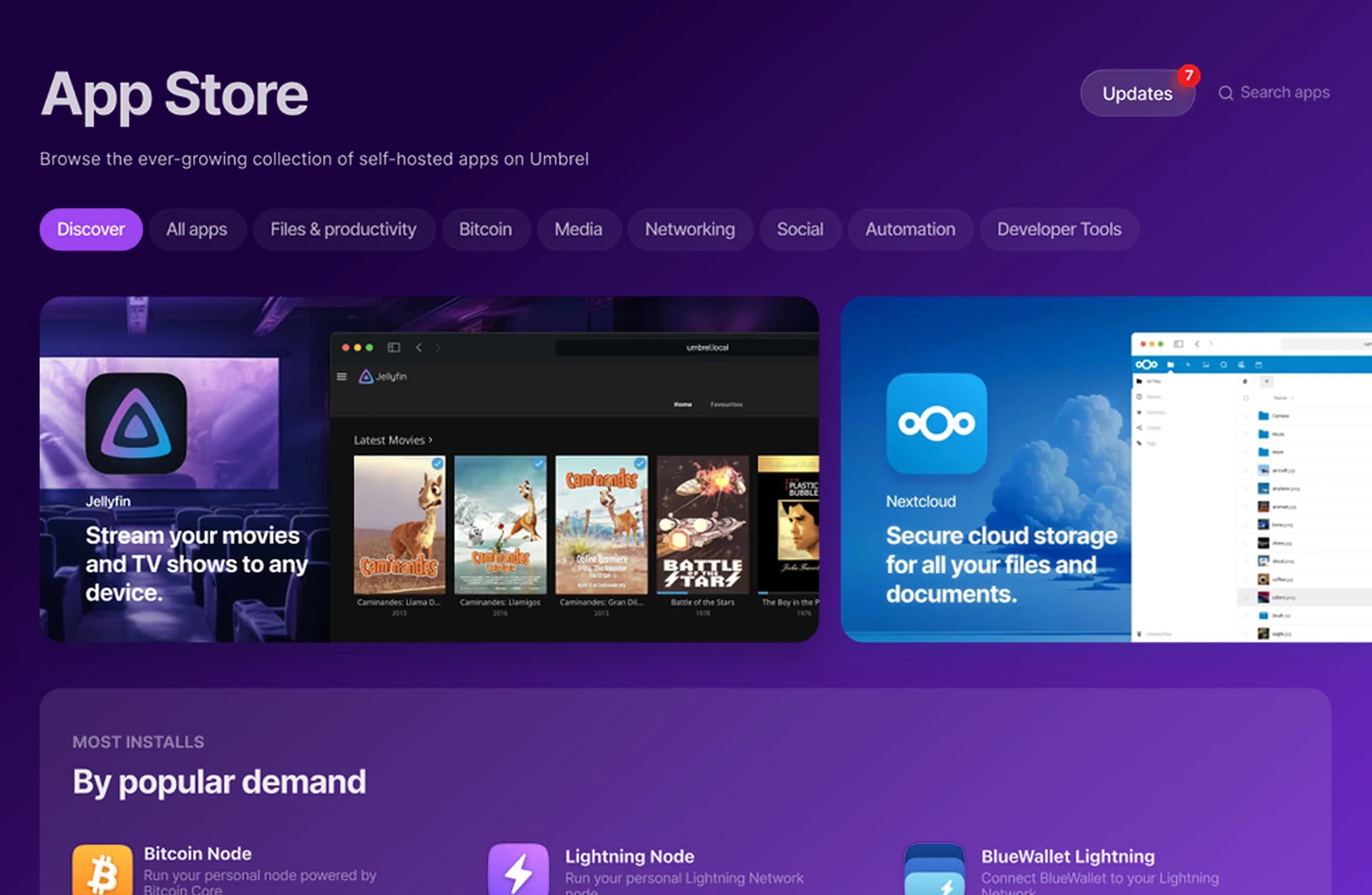
Train and Deploy, Your AI Agents

AMD Radeon 8060S
40 compute units (2,560 stream processors)RDNA 3.5
It delivers performance on par with NVIDIA’s mobile RTX 4070, enabling smooth AAA gameplay and efficient encoding/decoding for AVC, HEVC, VP9, and AV1 video codecs.

A Second Brain to the Whole Team
Running your own AI server and local AI models offers companies significant advantages in privacy, security, control, customization, and long-term cost savings compared to relying solely on cloud-based AI solutions.
 126 TOPS
126 TOPS
Ultra-High AI Computing Power
The XDNA2-based NPU delivers 50 TOPS AI performance, with total system power reaching 126 TOPS. In Windows 11 LM Studio tests, the Ryzen AI Max+ 395 outperforms the RTX 4090 by 220% in AI efficiency.

16 Cores
Number of CPU Cores
Zen5 CPU Cores
32 Threads
TSMC 4nm Process
80MB L2+L3 Smart Cache
5.1 GHz
Max Boost Clock
Max TDP: 140W
 2 TB M.2 SSD
2 TB M.2 SSD
 140W TDB
140W TDB

 128 GB RAM
128 GB RAM
 Black & White
Black & White

Train and Deploy, Your AI Agents

Local Server
Stores and runs your AI model securely on-premises.
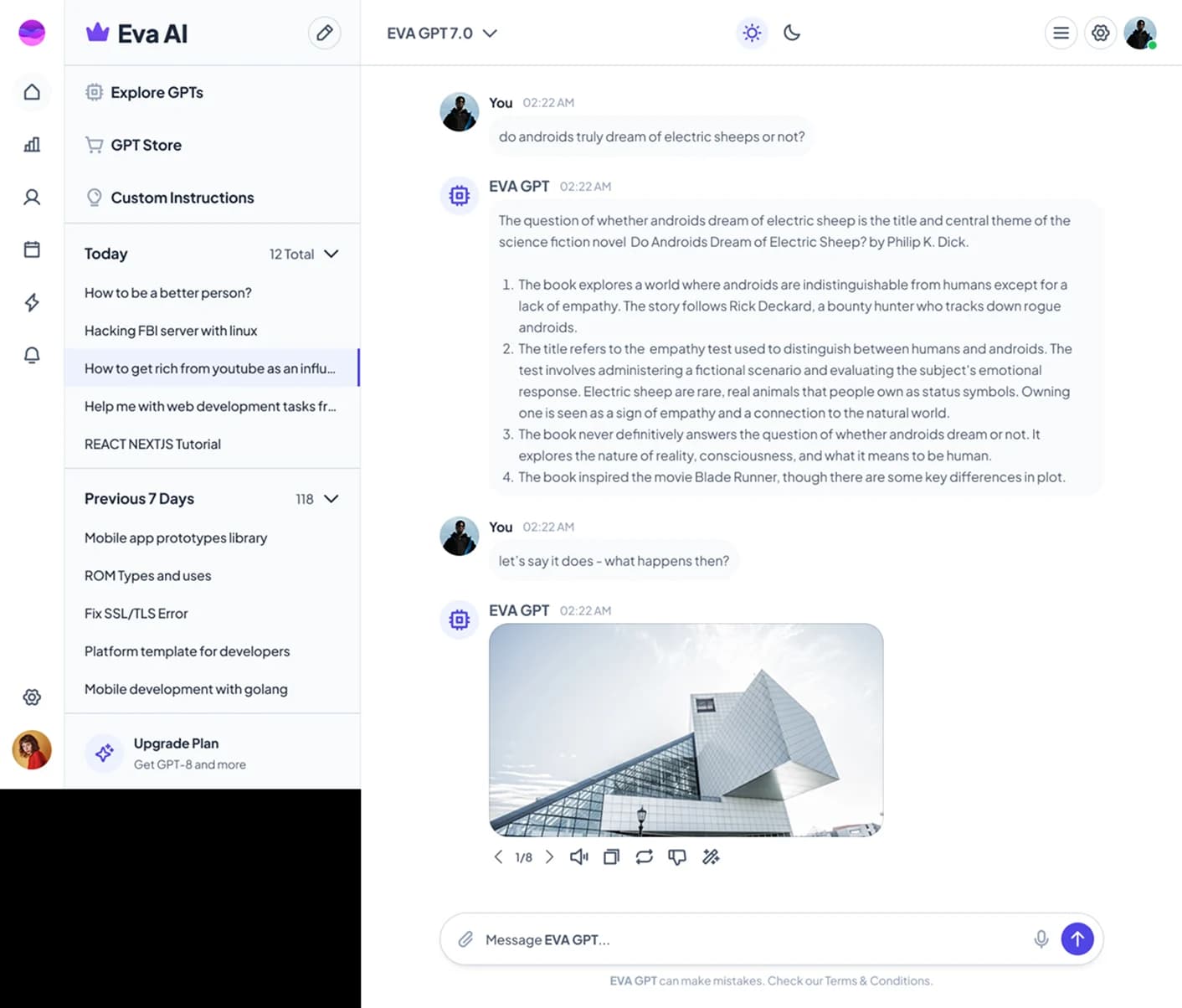
AI Model Interface
Connects the server to the AI system for processing requests.

Local AI Chat Agent
Understands user input, manages context, and generates accurate, real-time responses tailored to the conversation.